论文信息
原文:MAIN-VC: Lightweight Speech Representation Disentanglement for One-shot Voice Conversion
作者:Pengcheng Li, Jianzong Wang, Xulong Zhang, Yong Zhang, et al.
录用:IJCNN 2024, Yokohama, Japan
模型构架
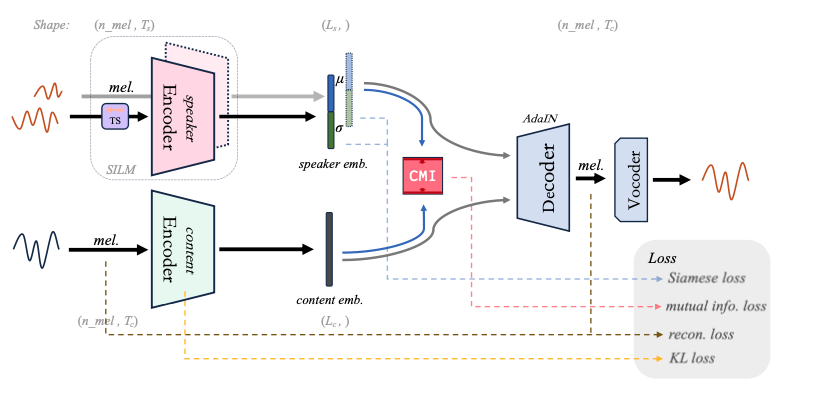
概述
语音转换(voice conversion)技术根据目标说话人的语料改变源语音的音色,使转换后的语音听上去由目标说话人说出。基于语音表征解耦(speech representation disentanglement)的方法具有灵活的优点但面临解耦不充分的问题。
在本文中,我们针对这些问题提出了一种使用互信息和孪生结构增强模型解耦性能的语音转换模型,通过最小化说话人身份和说话内容间的互信息上界,并将具有孪生结构的编码器组合用于更准确的说话人信息和内容信息的解耦。模型设计使用更轻量的结构,并通过在训练阶段增强编码器的学习能力,达到性能和体量的平衡。
实验结果表明,MAIN-VC与现有的模型在任意到任意的语音转换任务中表现相当甚至更优秀,并且在模型参数量(相交现有轻量模型减少约60%参数量)和推理速度(相较基线方法减少约80%推理时间)方面更具优势。
MAIN-VC的基础模型为AdaIN-VC,一种使用自适应实例归一化(adaptive instance normalization)进行风格迁移的语音转换模型。MAIN-VC对其进行了解耦能力强化和网络结构轻量化重新设计,以达到更理想的语音转换效果和更轻量化的神经网络结构。
本文强化模型解耦能力的主要思路为使用孪生编码器并配合数据增强手段(时序随机,time shuffle)来增强模型对说话人表征学习和提取的能力。引入内容表征和说话人表征间的互信息估计并在训练过程中最小化互信息以减少信息冗余、促进模型对两种表征的解耦。由于实验中发现互信息上界估计的不稳定问题,MAIN-VC中互信息估计网络使用了上下界联合估计的手段,即用两种不同的估计方法分别估计互信息的上界和下界,并缩小上下界之间的差异来提升互信息上界估计的准确性和鲁棒性,这样的上下解联合估计方法同时也使互信息估计网络以及整体模型的训练更稳定。
模型的基本结构为变分自编码器,需要运用大量的卷积模块进行表征解耦以及表征融合,为了减小模型体积(减少参数量、减短推理时长),MAIN-VC设计了一种空洞金字塔形残差卷积模块,该模块足够轻量且有更大的感受野,有望用于其他模型的轻量化设计中。此外,由于孪生结构和互信息的引入,模型的解耦能力不再依赖于复杂的网络设计对大尺寸中间特征的学习,通过减少模型中间特征的通道数以及整体的网络层数来进一步缩小模型的尺寸。我们在模型的性能和轻量化间维持了较好的平衡,在不到1.5M的参数量下,MAIN-VC能达到与现有方法相当的转换质量并具备快速的推理速度。
实验详细结果见论文pdf,转换效果可参考MAIN-VC主页 。
引用
如果MAIN-VC对您的研究有帮助,或用作baseline,欢迎引用:
1 | @inproceedings{li2024mainvc, |
Pechola
不來也不去.